“Machine Learning is the field of study that gives computers the ability to learn without being explicitly programmed” – Arthur Samuel
I took Andrew Ng’s Machine Learning course on Coursera last summer. This course gave me an entry point to the world of machine learning. The course touches upon some of the most widely used algorithms, and best practices in machine learning. There is some serious math involved, but it is not too difficult if you know linear algebra; some idea about calculus is also helpful. Andrew is a wonderful instructor, and he does an excellent job in explaining the concepts in an easily digestible manner.
I am revisiting this course now. I felt that I need to brush up on some concepts, and fill in the gaps of my understanding. I was going through my notes, and realised that I never put it online. To this end, I am writing a series of posts to explain what I have learned from this course. This is part 1 of the series.
What is Machine Learning?
It is possible to solve most of the problems we face through computer programming. For instance, think about finding the shortest path between two places, which can be distilled down to a graph search problem. However, no such solution exists for problems such as speech and image recognition, Web search, etc. So, it was decided to let machines figure this out by employing computational, and statistical methods, which later evolved into the field of Machine Learning. In a nutshell, machine learning grew out of the field of Artificial Intelligence (AI), to address problems that could not be solved through programming.
A more recent, and formal definition of machine learning by Tom Mitchell is given below:
“A machine is said to learn from Experience E on a Task T, based on a performance metric P, if the machine’s performance P on the task T improves with experience E.”
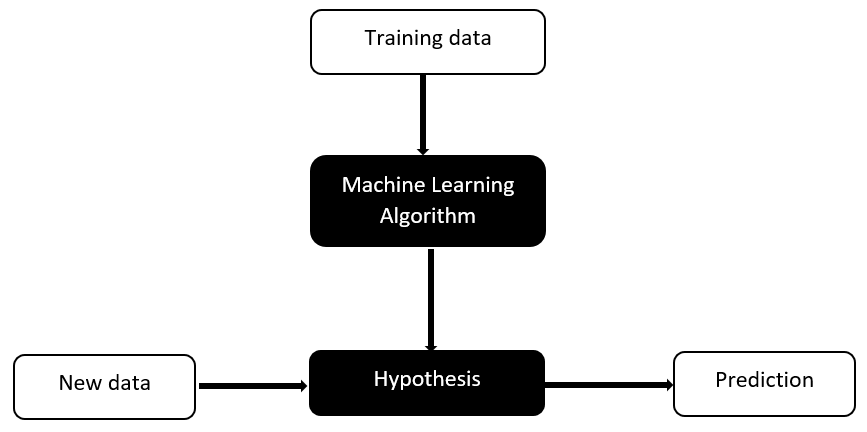
How does Machine Learning work?
A set of data known as the training data is provided as input. The training data is used to train a learning algorithm, which produces a hypothesis as the output. The hypothesis is nothing but a statistical model that can be used to make future predictions. It can be thought of as a function that produces an output parameter -the prediction- when it receives an input parameter.
Types of Machine Learning
There are many kinds of Machine Learning techniques. The most widely used ones are Supervised Machine Learning and Unsupervised Machine Learning. Besides these, there are many other techniques, such as, Reinforcement Learning, Recommender Systems, etc.
Supervised Machine Learning
In Supervised Machine Learning, the system is given a dataset with the several features. One of these features is the feature of interest that we wish to predict. The system prepares a statistical model based on the given data. The model can then be used to predict answers for a problem that is previously unseen by the system. For example, consider how SPAM filters work. The model classifies an email as SPAM based how similar it is to historical data. Predicting housing prices is another example, where we train a model on various attributes of a house, such as, the living area, locality, number of bedrooms and bathrooms, and price.
Supervised Machine Learning can be further sub divided into Regression, and Classification. In a Regression problem, the model tries to predict a continuous value. The housing price prediction is an example for a Regression problem. In a classification problem the model tries to assign the value to a discrete category. When number of categories is two, it’s known as binary classification, and when it involves multiple categories, it is multi-class classification.
Unsupervised Machine Learning
In Unsupervised Machine Learning we do not have a clear idea on how our results would look like. Unlike supervised machine learning, we also do not have nicely labelled datasets. Clustering is the most common unsupervised machine learning technique, which essentially groups similar as clusters. News aggregators such as Google News, customer profiling used by corporations to understand market segmentation, etc. are examples for Clustering. Independent Component Analysis (ICA) is another example for unsupervised machine learning. It is used to filter out audio from noise, and extracting foreground information from background in images.
In the next part, we shall look at one of the most basic supervised learning algorithm: Univariate Linear Regression, or Linear Regression with one variable.